Designing Smart Software: A Generative.fm UX Case Study
Balancing UX and design effort on a side project
I'm a software developer with no professional design experience. But for my projects, I like to pretend I'm a designer too.
Back before Generative.fm had user accounts, user data was stored only on the devices being used to access the service. As long as a user didn't clear their browsing data—does anyone still do that?—the service accumulated their data over time and was used to improve the experience. This worked well enough for a while, but eventually users were asking me to add accounts to store and sync their data between devices.
As I started exploring the addition of user accounts, I realized there were some major design decisions to make about how the service would handle user data. For example:
- Should a user be required to make an account to use the service?
- Should user data still be accumulated on devices even when the user hasn't logged in?
- What should happen to anonymously-accumulated user data on the device after the user logs in?
These questions deserved thoughtful answers, and I'm satisfied with the result I arrived at. Here's how I did it.
First, a little context
Generative.fm was launched in 2018 and started getting mild attention in 2019. I didn't add user accounts until early 2021. That meant users had up to 2–3 years of data accumulated on their devices. In many cases, a user could have their data spread across multiple devices.
The most important user data was the total duration of music played and a list of generators marked as favorites. The criticality of this data is debatable. The list of favorites could be easily recreated, and the total play time is only used to present a user's most played generators to them—another list which would probably recreate itself over time should a user's data be reset. One could make an argument for simply starting each user account off with fresh data, and deleting any data already stored on the device.
However, it wouldn't be very considerate of Generative.fm to just wipe away this data once a user makes an account. One of the design principles from About Face: The Essentials of Interaction Design by Alan Cooper et al. is, "Software should behave like a considerate human being." Recreating the data might be easy, but it's not trivial. Also, many users have mentioned they love seeing their total play time in Generative.fm, and taking that away from the folks who took a chance using my little service in its infancy just wouldn't feel right. I wouldn't be surprised if that approach would have convinced users to leave my service and never come back.
I decided it was worth the effort to move the data into user accounts. But how should that work?
How to design anything
The greatest advice I have ever seen for designing anything is from the book About Face: The Essentials of Interaction Design by Alan Cooper et al. Here it is:
In the early stages of design, pretend the [thing you're designing] is magic.
The reason this works so well is it frees your mind from any practical limitations. If you had a magic wand and could simply will the perfect solution to your problem into existence, what would it be? Once you have clear idea of the perfect solution, then you can either figure out how to get it done, or get as close to it as possible. Sorry to use a buzzword, but this is where innovation comes from.
Let's look back at the questions I listed above, pretend Generative.fm is magic, and decide how they should be answered:
- Should user be required to make an account to use the service? No, that's annoying.
- Should user data still be accumulated on devices even when the user hasn't logged in? Yes, it improves the experience of using the service.
- What should happen to anonymously-accumulated user data on the device after the user logs in? If that data belongs to the user who logged in, it should be added to their account. If it doesn't, it should not be added to their account.
The first and second answers are easy enough, but the third is pretty magical. How would Generative.fm know whether the anonymously-accumulated data belonged to the user who logged in?
I thought about this a bit and never came up with an answer. Since devices can be shared between users, Generative.fm simply can't assume who the data belongs to. The perfect solution isn't possible in this case, but that's okay.
Solution #1
At this point I started thinking about how close to the magic solution I could get. The correct behavior hinges on whether the anonymous data was generated by the same user logging in or not. The service has no way of knowing this, but the user does. So, maybe Generative.fm could just ask them.
My first solution looked like this:
- When a user logs in, check for any anonymously-accumulated data. If there is some, show a summary of the data to the user and ask whether they'd like to add it to their account.
Easy enough, but could it be better?
Solution #1.5
In the book Microinteractions: Designing with Details, author Dan Saffer explains how we can design better interactions with software by asking ourselves, "What do I know about the user and the context?" Specifically, he recommends considering what a user has done in the past to make smarter decisions about what they want to do in the future.
When asking a user what to do with the anonymous data, Generative.fm could either remember their choice and automatically do it again next time, or give them an option like "remember this next time." This is an improvement, but I wanted to get even closer to the magic solution.
Solution #2
The first solution would have worked okay, but I felt Generative.fm could be a little smarter.
What does it mean for software to be "smart?"
Imagine you're hiring an assistant. Which of these descriptions would you prefer they fit?
- An assistant who idly waits until you tell them to do something. If they encounter something unexpected while completing a task, they stop to ask you how to proceed. They make no assumptions about when or how you'd like things to be accomplished and constantly seek your guidance so as not to make a mistake.
- An assistant who anticipates your needs and takes actions without your explicit instructions, and gives you a brief report once they've finished. It's almost as if they can read your mind. Occasionally they do something wrong, but upon correction they undo the action and remember not to do it again.
Surely we would all prefer someone who takes initiative and learns our needs over someone who needs constant direction. You would probably have very different assessments about how smart each type of assistant must be.
Software should behave like a smart assistant. It should anticpate your needs and take actions without you telling it to. But, those actions should be easy to undo, and the software should learn from its mistakes.
I considered two groups of users who'd be affected by how anonymous data was handled:
- Users with an account who didn't share their device(s)—or more accurately, their user profile(s)—with anyone else. They'd have to see the prompt when they logged in if they'd used the service anonymously—like if their session expired and they didn't log in right away. These users probably want the data added to their accounts.
- Users with an account who did share their device(s) or user profile(s) with others. If the other users didn't have an account, their data would be accumulated anonymously. The users with an account would see the prompt when they logged in after someone had used Generative.fm anonymously. These users probably don't want the data added to their accounts.
If Generative.fm were a real company, or I were a real designer, at this point I would have started interviewing users to find out whether these groups are accurate and how many users occupied each. Since I'm just a lone developer with limited time and merely moonlighting as a designer, I made some assumptions instead.
I assumed the majority of users would fall into the first group. Most people who use a smartphone probably don't share it with others, and many have their own computer too. Those who do share devices probably use their own OS-level profiles, which means their browser data would already be kept separate from the other users of the device. Finally, even if more than one person shares a user profile on a device, it's probably more likely that only one of them uses Generative.fm, or that everyone who does use it will create their own account. I think these are reasonable assumptions.
With that in mind, it's seems very likely that any user logging in will want to have any anonymous data added to their account. Most of the time, the smart behavior is to just add the data to their account right away without asking.
But I didn't want to alienate users who share devices; they should be able to remove the anonymous data from their account. Just like the previous solution, we can probably assume a user who didn't want anonymous data added once probably won't want it added ever, so Generative.fm should remember the decision. But users should also be able to re-enable the automatic import if they want.
Ultimately, the solution looks like this:
- When a user logs in, check for any anonymously-accumulated data. If there is some, and the user hasn't disabled this behavior, add it their account.
- Notify the user that anonymous data was added to their account. Show them a summary of the data and enable them to remove it from their account.
- If the user chooses to remove the data from their account, disable the behavior described in step 1, but give them the option of enabling it again at any time.
Comparing solutions
The second solution is significantly more complicated than the first, but let's consider how it affects people who use Generative.fm.
Imagine the users of the service are distributed in the categories described previously like so:
- Users who don't share their device/OS user profile and want the anonymous data added every time: 80%
- Users who do share their device/OS user profile and don't want the anonymous data added every time: 20%
Note that these are probably very conservative guesstimates—I'd bet the number of users in the first category is at least 90% or more.
In the first solution, where Generative.fm would ask every user what they'd like to do with the anonymous data, 100% of affected users are forced to make a decision and take some action at least once. But in the second solution, 80% of affected users have the right choice made for them automatically, and the other 20% are notified of the action and given the ability to easily reverse the behavior.
Remember, if Generative.fm was magic, it would just know what to do with the data. That's probably not possible, but it can make the right decision for the vast majority of users without upsetting the rest. That's clearly preferable to just stupidly asking everyone what to do while it already knows what the right answer probably is.
Implementation
When a user logs in on a device where anonymous data was detected and importing it is enabled (which it is by default), they're shown this alert:

Most users will see this and probably think something like, "Wow, that was really smart. Thanks!" and hit "Dismiss." Clicking "Learn more" displays the following dialog:
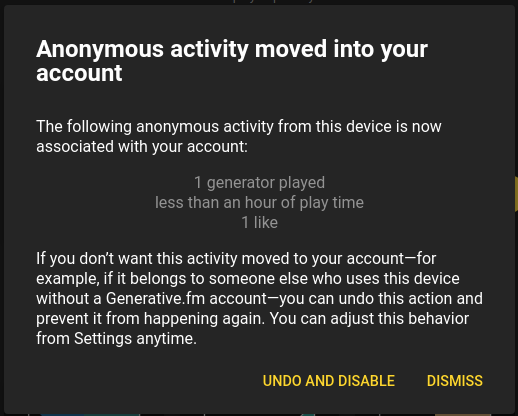
This dialog gives the user all the information they need to make a choice and even gives them an example as to why they might want to disable the behavior. Again, most users will probably see this and go "Cool, yup, that's my data from when I wasn't logged in." If not, they can hit "Undo and disable" and never see it again.
Over in the settings, users have this toggle to control the behavior:
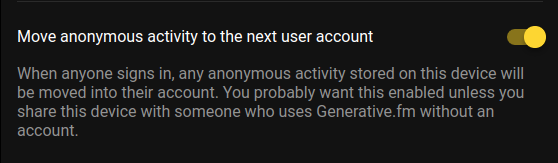
Again, this not only describes the setting but also gives some guidance for the user to decide whether it should be enable or disabled. If the user disables this in the same session that anonymous data was added, that data is removed. Likewise, if they enable it after logging in to a session where some anonymous data was previously accumulated, that data is added to their account and the banner is displayed.
A little design effort goes a long way
It's intimidating to take on design challenges as a developer. For personal or side projects, we often have no choice but to try. But there's a simple procedure for approximating good design decisions:
- Pretend you can magically make any software you imagine at the snap of your fingers. Forget about limitations like security, storage space, processor speed, and engineering time—your software will be magical. What would it be like? How would it work?
- Now reintroduce all the constraints imposed by reality, but use your imaginary software as an idealized goal. What would it take to build it for real? Can you come up with something close to it you can actually make?
With this approach, I feel more confident when faced with design problems. I'm very pleased with how Generative.fm handles user data without requiring an account, and I've received positive feedback from users about the experience.
At its core, design is just imagining solutions to problems. We all do it, every day!